

Who Controls AI, and What Could Loosen the Grip?
The physical limits now bending the data-center buildout, and the three technical counterweights that leave frontier AI without a single off switch.

June 20, 2026
The frontier AI industry is both extremely concentrated and dominated by private enterprises. The most powerful artificial intelligence in the world is built by only a few companies, in a few buildings, in a few countries.
On June 12, the US government ordered Anthropic to suspend access to Fable 5 and Mythos 5, its two newest frontier models, for any foreign national. Because citizenship cannot be verified across millions of users in real time, the only compliant move was to switch the models off for everyone, and they were gone worldwide within hours. Opus 4.8 and the older models kept running.
As of writing the dispute is unresolved and the two models are still dark, the clearest demonstration yet of how fragile the average user’s access to frontier AI has become.
Before this, using Claude or ChatGPT was as simple as paying for a subscription or an API key. There were whispers of “Sovereign AI,” or using “open weights” models running on local machines, but most people just used Claude, until their access was revoked.
By now it’s clear what’s at stake: access to the most powerful artificial intelligence in the world. Because of the industry’s concentration and composition, access can be modified or revoked at any time, even to paying customers.
As we’ve written before, control typically only matters once it’s lost, and in the wake of this controversy, individuals, companies, and countries are looking to design robust AI stacks that don’t depend on continued access to a frontier lab.
Frontier AI is and will remain concentrated because training requires enormous, visible, governable infrastructure. But useful AI is becoming less dependent on hosted access, because inference, weights, and training are each beginning to escape the frontier labs in different ways.
Why Control Concentrates…
Frontier concentration starts as an engineering requirement. The best models are thus far often the largest models, and training them requires tens of thousands of accelerators in the same place, wired together with enough bandwidth to minimize latency and synchronize the whole cluster on every step.
This kind of enormous clustered hardware is also extremely expensive, which is why the frontier labs are some of the most capital-intensive businesses in history. Together they form a loop: you need capital to build the models, but you need good models to raise the capital. Only a handful of companies satisfy both conditions, which is why access to the frontier is permissioned.

The leading labs keep the parameters closed because access to the model is the product. Releasing the weights means there’s nothing left to sell, so the labs don’t make the parameters of their models available or downloadable. Users can’t own their own versions of Claude or ChatGPT. Instead, these models are made available as a service users can pay for using accounts, subscriptions, or APIs.
Access sold as a service can be throttled, revoked, or switched off, all of which happened to Fable.
…and Where the Cracks Are Showing
The same requirements that concentrate the frontier are now making it harder to expand, for reasons that have nothing to do with algorithms.
Training clusters are scaling toward the gigawatt range. xAI’s Colossus is moving from 350 MW toward 1.5 GW and OpenAI’s Abilene site is expanding to 1.2 GW, with projections of 10 GW runs by the end of the decade. The grid as currently designed cannot keep pace.
But the bottleneck isn’t just available power generation, although the specialized equipment required to expand the grid is back-ordered.
Perhaps more importantly, the towns are voting the buildings down, even though only about 8 percent of Americans live near one. In the first quarter of 2026, community opposition blocked or delayed data center projects worth about $130 billion, the largest single quarter on record, with active opposition groups more than doubling to 833 across 49 states. New York’s legislature passed a one-year moratorium on large data centers, awaiting the governor’s signature, and Maine passed one before its governor vetoed it (and Europe is way ahead of the US on protests).

Clearly none of this halts the buildout or reduces demand for frontier models, but it raises the cost and slows the pace of development. Many people will continue to demand the best available models, but viable alternatives are improving and getting cheaper.
These alternatives center on three basic questions:
Can you own the model?
Can you run the model yourself?
Can new models be trained without the incumbents?
Open Weights
Start with ownership. Can a user possess the model at all? Access control with Fable is a case in point: when access is the product, access can be withheld. With open weights, the trained parameters are released for others to download, copy, and serve independently.
Possession would matter less if it required accepting a large drop in capability. For years, open models consistently underperformed the frontier such that they weren’t capable enough to rely on for anything meaningful.
Increasingly, that’s no longer the case. The best open models are now close enough in capability to the frontier that they’ve become practically useful, and for much cheaper than the frontier.



The numbers now support that shift. The Stanford AI Index put the closed-model lead near 3.3 percent in early 2026, and on individual tasks the best open models have already drawn level. Z.ai’s GLM-5.2, a roughly 750-billion-parameter mixture-of-experts model with a one-million-token context and an MIT license, scores 62.1 on SWE-bench Pro against GPT-5.5’s 58.6, at about a sixth of the cost, while still trailing Opus 4.8 on most coding head-to-heads. DeepSeek, Qwen, Kimi, and Llama sit in the same tier.
The practical point is simple: most work doesn’t require the frontier in the first place. It only requires a model good enough to clear the task’s threshold. Once an open model is good enough for the task, the marginal improvement in capability of a closed frontier model isn’t worth as much as control over the model itself. Open weights models have now definitively hit that threshold, and they continue to improve as well on more challenging benchmarks.
The same distinction applies to jurisdiction. Running GLM through Z.ai’s cloud subjects the traffic to China’s National Intelligence Law, which may be as unattractive as routing through the US labs. But downloading the same weights and serving them yourself means you’re beholden to no one. The model may be identical, but the dependency is different. In addition, services like Venice.ai offer hosted versions of the open-weights models, with some promises of privacy.
Open weights therefore provide control in ways that closed models can’t, but they don’t remove every dependency.
A downloaded open weights model still has to run somewhere, and if it runs through another hosted endpoint (as in the GLM Z.ai cloud example), the user’s only shifted the dependency to a different provider. The question of independent training comes later. First comes the more immediate problem: once the weights exist, can the user run them without a provider?
Running Models Locally
If open weights mean a user can own the model, local inference means they can use the model without a provider.
For most of the past few years, using a capable model meant sending a request to a provider’s data center, where the provider supplied the compute, saw the prompts, and controlled continued access.
That is changing because local hardware has become strong enough to run models that recently would have required much larger systems. NVIDIA’s DGX Spark, roughly the size of a large paperback, pairs a GB10 Grace Blackwell chip with 128 GB of unified memory and NVFP4 four-bit precision to run models up to around 200 billion parameters locally, or roughly 405 billion with two units linked over a 200 Gbps interconnect. Apple’s unified-memory machines do something similar through the MLX stack. Aggressive quantization makes much of this possible by reducing the memory required to run large models, albeit at the cost of some loss in quality.
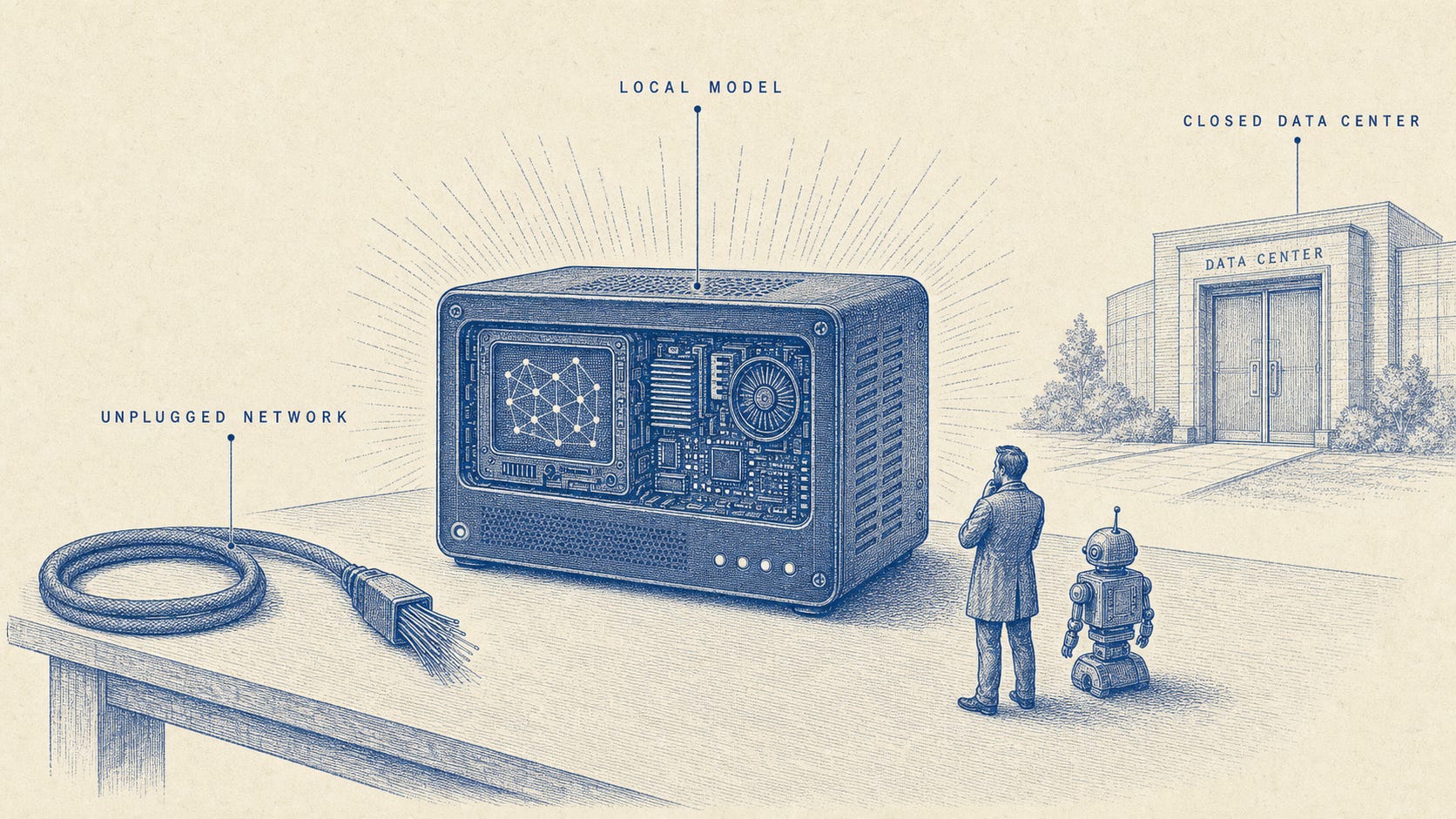
When the weights run on a user-controlled machine, the model can run “locally” without an internet connection, so use no longer depends on a live provider. There is no provider logging prompts, no hosted endpoint that has to remain available, and no subscription required for the model to keep working. Continued access, therefore, is no longer mediated by an intermediary.
There is, however, a limit. Users can own open-weight models after they have been trained and released, and they can increasingly run those models locally on machines they control. But as discussed earlier, developing new frontier models, open or closed, still depends on the concentrated training infrastructure that narrowed the industry in the first place.
Whereas open weights and local inference reduce dependence once the model exists, training determines who can create the next one, which is why it remains the hardest dependency to break.
Training Without the Giants
The last dependency is training itself: can new models be built without the companies that own the largest clusters?
Training is the part of the stack most tightly bound to concentration, but it is not monolithic, and the costs split sharply depending on which half you mean.

Pretraining a base model from scratch is still the concentrated, frontier-capex half. Post-training, which now drives much of a model’s capability, has detached from that scale. Prime Intellect (a Nazaré portfolio company) has shown reinforcement learning at trillion-parameter scale on open mixture-of-experts models: with its open-source prime-rl stack it post-trains GLM-5 on long-horizon software-engineering tasks at 131k context, with sub-5-minute step times, on 28 H200 nodes, and the same recipe runs on Kimi and Nemotron.
Roughly 224 GPUs is a cluster a neolab or a well-funded company can rent, not a hundred-thousand-chip buildout. The step the labs assumed was their moat, the reinforcement learning that turns a base model into a capable agent, now runs on modest compute with open code. Reinforcement learning also distributes more naturally than pretraining, because the rollouts that dominate its cost run asynchronously and in parallel rather than locked in lockstep across one fabric.
The dependency does not disappear; it moves up a layer. Post-training runs on top of an existing open base model, and those still come from a handful of labs with frontier pretraining clusters, most of them Chinese. Cheap open post-training is real, and it rides on someone else continuing to release a frontier-scale base to build on.
Building that base without the giants is the harder, slower frontier. Covenant-72B, a 72-billion-parameter model from the Templar team, was trained across about seventy permissionless peers over commodity internet, with no whitelist and no central operator, using SparseLoCo to compress communication by about 146 times and a trustless validation scheme to keep anonymous contributors honest, at 94.5 percent compute utilization. It scored 67.1 on MMLU, slightly ahead of Llama-2-70B. That shows decentralized pretraining works, but lands years behind the live frontier.
Epoch AI judges it likely to be feasible at frontier scale in the future and suggests it is growing at nearly 20 times a year, four to five times faster than centralized training is scaling, while still unlikely to gather frontier-level compute this decade. The sign that this is becoming infrastructure rather than a stunt: Prime Intellect now sits in the NVIDIA Nemotron Coalition, contributing post-training infrastructure and 2,500-plus reinforcement-learning environments, with Nous Research and Pluralis training by the same logic.
Will the Open Stack Reach the Frontier?
The open stack can probably reach last year’s frontier, and on post-training it is already there. Reaching the live frontier is harder, and the obstacles are pre-training scale, private data, and funding rather than post-training compute.
“The frontier” can mean two different things. If it means the best model from 18-24 months ago, decentralized training is close enough to take seriously. Money is now the binding constraint: can these projects keep paying for large runs once the coordination problem looks solved?
If it means the best available model at any given point in time, the answer is probably not this decade, and possibly not ever. Distributed training can only gather so much spare compute, and the leading labs are still accumulating more.
There’s also recursion to take into account: the frontier improves every year in part because the labs use their own models to help build the next ones, so the pace of improvement quickens.
The strongest case for distributed training is efficiency. The compute required for a given level of capability keeps falling, and DeepSeek trained a competitive model for roughly a twentieth of a comparable budget. If that continues, decentralized training won’t need to match the frontier’s raw compute directly, because the amount of compute needed to reach a useful level keeps falling.
The harder limit is everything that has not come loose. The base models still come from a few frontier pre-training clusters, and the frontier’s edge increasingly sits in proprietary interaction data and in reward design for fuzzy, hard-to-verify work, where you cannot simply check the answer. Open post-training bites hardest in verifiable domains like code and math, and least where the reward itself is the moat.
Funding is also unresolved. No legitimately durable way to pay for community-scale training has emerged, so even if the technical path works, the money for the largest runs may never materialize.
The Common Property
Open weights, local inference, and distributed training are at different levels of maturity, but they share the same basic property: they reduce dependence on permission from a frontier provider.

The frontier will always be important, but it may also become inaccessible, illegal to use, or nationalized outright. As long as they survive, the largest labs will preserve advantages in capital, infrastructure, data, talent, and post-training, and many users will keep paying for the best hosted models when the work justifies it.
But the hosted frontier no longer has to be the whole stack. A company, country, or individual can use frontier access where it’s most valuable while keeping enough capability outside the hosted channel to survive disruptions in service.
After Fable, that’s the standard a serious, sovereign AI stack has to meet: when a provider stops granting access, useful AI must live on.