

The Forgotten Path
Algorithm Innovation in the Age of AI Scale

Before Charles Babbage was inspired to design the Difference Engine and Analytical Engine – launching the age of mechanical computing – the first AI engineers were “Pre-Babbage” workers performing complex mathematical calculations by hand. The English navy required accurate logarithms for navigation and these were calculated by people by hand, with the work carried out at home or remote offices.

The first computer network was distributed and human.
Babbage’s revolution was aggregating and automating the calculations that were being done by hand, as opposed to the alternative of simply hiring more humans. He had a vision to centralize the network and scale it. Babbage’s machine was never used in production, with the only working version made in 1991 by the London Science Museum.
This historical reality belies a profound truth: once a powerful computational substrate exists, innovation can thrive not only by scaling the substrate itself, but by developing better methods to harness what's already available.
At our current stage of AI evolution, that means innovating algorithms and AI system design, not just adding data centers and NVIDIA racks.
The Imbalance in Modern AI Progress
Our approach to AI improvement has heavily favored one path forward: scaling compute.
Since 2012, the computational resources used to train frontier AI models have increased by many orders of magnitude. Transformers, the go-to architecture for models, have grown from millions to hundreds of billions of parameters.
Each new model iteration primarily follows a familiar pattern: more layers, larger context windows, more training tokens, more GPUs.
This scaling approach has yielded impressive results. GPT-4, Grok, Claude, and similar models demonstrate capabilities that seemed impossible just years ago. The power of scale is undeniable.
But hyperscaling is encountering challenges. Though by no means a certainty, we are at least considering the possibility that there may be an upper bound to scaling compute.
Training costs for frontier models are excessive
Energy consumption rises dramatically with each generation
Inference remains expensive, especially related to local applications on edge devices
As such, improving algorithms is the logical next step. Instead of trying to build an ever-larger base layer, we should be asking: How can we improve this foundation to unlock even more performance, utility, and sustainability?
DeepSeek's R1 was a wake-up call, demonstrating the potential of algorithmic innovation in achieving comparable results with far fewer resources. Yet despite causing a brief market correction, we have since doubled down on scaling with a vengeance.
The Complementary Path Forward
Continued AI development lies in rebalancing our approach to pursuing both scale and algorithmic innovation. Algorithm improvement may even prove to be more robust, sustainable, and profitable than hyperscaling brute force compute alone. Consider how algorithm improvements have already transformed AI capabilities to date:
Mixture of Experts (MoE) (my PhD research domain) architectures demonstrate this complementary approach perfectly. Rather than activating the entire model for every token, MoE systems engage only a small subset of "experts," each neural network handling a specialized domain. Instead of opposing scale, they make scale more efficient. Google's Switch Transformer takes this approach, achieving better results than dense models of the same size while activating only a fraction of parameters for any given input.
State Space Models like Mamba have recently challenged the transformer's dominance by replacing attention mechanisms with recurrent state space equations. This algorithmic shift reduces computational complexity from quadratic to linear while maintaining or improving performance on certain tasks. Mathematical innovation can unlock new efficiency frontiers even as models continue to grow.
RWKV (Receptance Weighted Key Value) represents another compelling example of algorithmic innovation delivering efficiency gains without sacrificing performance. This architecture combines the parallelizable training advantages of transformers with the efficient inference characteristics of Recurrent Neural Networks (RNNs), achieving what many considered impossible: linear computational complexity instead of the quadratic scaling that plagues traditional attention mechanisms.
Liquid Neural Networks from MIT exemplify how algorithm design can extract more capability from smaller models. Inspired by biological systems, these networks use continuous-time neural dynamics to achieve performance with fewer parameters. When deployed on autonomous vehicles, they demonstrated capabilities that once seemed to require much larger models.
What We Forgot: Sweetening the “Bitter Lesson”
“The biggest lesson that can be read from 70 years of AI research is that general methods that leverage computation are ultimately the most effective, and by a large margin…the only thing that matters in the long run is the leveraging of computation.” - Rich Sutton
In our obsession with scale, we forgot that intelligence isn't just about horsepower. Algorithmic innovation creates leverage and unlocks new capabilities without doubling infrastructure.
Perhaps most importantly, it aligns with how intelligence works in the real world. Humans don’t grow new brains every time we face a harder problem. We learn better methods. We remember how we accomplished things in the past. We specialize. We adapt.
The Scaling Law: Moore’s Mirror Image
Commonly perceived as a smooth exponential curve doubling transistor density every two years, Moore's Law was actually a series of paradigm shifts every time we thought it was broken. From planar transistors to FinFETs, traditional lithography to extreme ultraviolet scanning, and two-dimensional to three-dimensional chip architectures, each transition created periods of uncertainty, skepticism, and temporary performance plateaus.
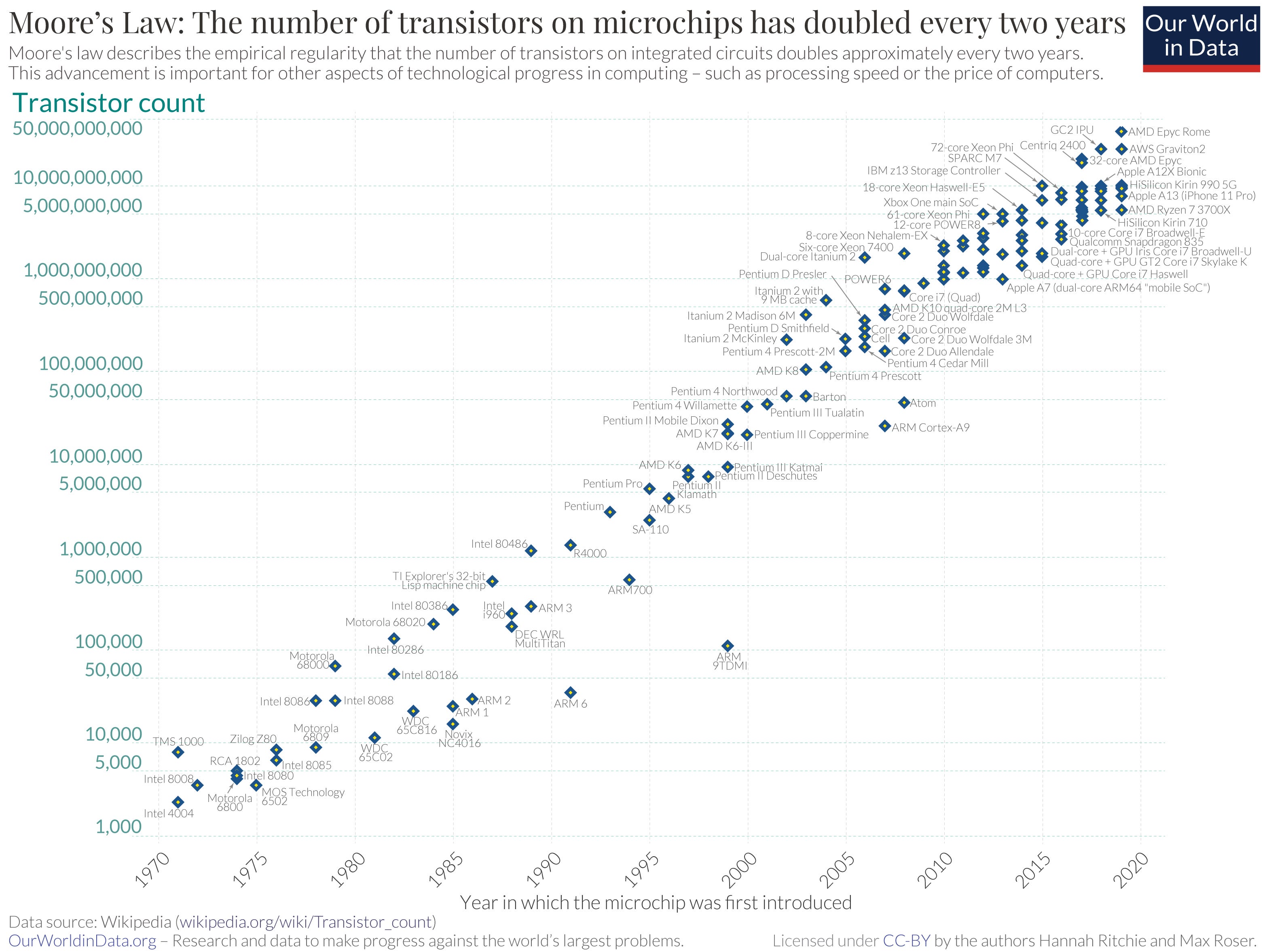
In fact, industry observers regularly declared Moore's Law dead during these intervals, only to be proven wrong by the next architectural breakthrough. Exponential progress simply doesn't occur in linear fashion over time. It happens through large leaps that create new performance frontiers while the underlying constraints appear insurmountable.
We can observe the same trend in AI:
From 2012-2016, combining commodity GPUs with data-parallel training created the steep AI-and-Compute curve that far exceeded Moore's traditional cadence.
2018-2020 saw the emergence of power-law scaling and the Transformer, demonstrating that making models wider and deeper continued to pay dividends when data and compute scaled together.
In 2021, Mixture of Experts (MoE) architectures represented the first major algorithmic paradigm shift – sparse activation allowing only 1-10% of parameters to fire per token, enabling capacity to scale without linear flop cost.
This was followed by compute-optimal rebalancing in 2022, FlashAttention enabling 100k+ token contexts in 2023, and DeepSeek's 2024 demonstration that 236 billion-parameter models could run efficiently on commodity hardware.
DeepSeek-R1 showed that frontier performance could now fit on a single high-end GPU – a breakthrough driven entirely by algorithmic efficiency rather than transistor count improvements.
Each of these transitions occurred precisely when the previous scaling approach appeared to hit fundamental limits, be they computational, economic, or architectural.
In other words, Moore’s Law and AI scaling laws are both empirical regularities, not laws of physics. They survive through discrete breakthroughs that shift constraints – from extreme-ultraviolet scanners in the fab to sparse-expert routers in an LLM stack.
The next decade’s “step changes” will look less like bigger chips and more like even better algorithms wringing even more from every flop and token – just as MoE and DeepSeek are doing today.
What’s Next?
The DeepSeek “moment” was a wake up call to AI researchers everywhere. Rather than having to raise billions in a seed round, founders can develop new algorithms to improve scaling at a fraction of the cost. Some promising areas of innovation include:
Decentralized models: from inference to more recently training and reasoning data generation, the rise of decentralized AI algorithms over the last year has brought attention to an overlooked area of research. Companies such as Prime Intellect (Nazaré portfolio company), Gensyn, Nous Research and Pluralis are pushing the boundaries of what was thought possible. If models can be training across wide area networks, more competitive and open compute solutions can be sourced and developed.
Heterogenous compute : the “Tower of Babel” analogy we introduced a few episodes ago spoke of a specific algorithm (the Transformer) to which one adds more data and more compute. The compute has to be the same in this tower - as in if you want to upgrade your cluster you upgrade the entire cluster not part at a time due to differences in FLOPs and memory bandwidth. Simply put - the algorithm is not designed for heterogenous compute. This leads to high cost for replacement and upgrades and lack of flexibility in general for companies developing and using AI models. This will be solved in part by decentralized models which can be designed to be less sensitive to compute homogeneity but some companies such as Modular and of course TinyCorp are focused on removing the dependence on Nvidia chips and CUDA software.
Balanced Progress
At Nazaré Ventures, we believe in the power of both paths: continued scaling where appropriate, combined with renewed emphasis on algorithmic innovation. Right now enormous investment is going into making AI’s data centers and data streams bigger, and what’s needed is a capital injection into the research and design of better models.
This will take private sector investment in startups challenging the algorithmic norms as well as public sector funding of academic research.The teams pioneering this space are pursuing the same goal as those early human computers: deriving maximum value from available computational resources through mathematical ingenuity and exceptional system design.
The truth is we’re sitting on tremendous brains…and we’re still figuring out how best to use them.
The next leap in AI will come not just from more powerful substrates, but from more ingenious ways to harness the power we already have. As history shows, it's sometimes the forgotten tools, the elegant methods, the quiet breakthroughs that change everything.