

NeurIPS 2025 Dispatch: AI Is Entering Its Algorithmic Phase
Yejin Choi on jagged intelligence, prolonged RL, and gradient-guided data diversification—signals that “more compute” is no longer the whole story.

Let me start by saying how blown away I was by the quality of NeurIPS, which I attended in San Diego a month ago. I’ve lived through multiple tech cycles, but the density of talent focused on AI today is unprecedented.

I attended Yejin Choi’s excellent talk titled The Art of (Artificial) Reasoning. It made a number of points that align with Nazaré’s thesis, and I’d like to cover them briefly below. To begin, Dr. Choi’s research focuses on democratizing generative AI through smaller yet powerful language models, scaling intelligence via smarter algorithms, alternative training recipes of language models, pluralistic alignment, and AI for science and social good.
Regular readers of Robot Wave will recognize many of these ideas. In her keynote, Choi opened with a reflection: despite brute-force scaling of LLMs driving rapid benchmark gains, today’s models exhibit what Choi calls “jagged intelligence.” In other words, their capabilities are uneven and spiky – strong on some tasks yet surprisingly brittle on others.
As everyone is familiar with, Richard Sutton’s Bitter Lesson argues against trying to use human techniques to improve machine intelligence – the most effective techniques are compute- and data-intensive. More data, more compute, better results. (Even if Dr. Sutton “doesn’t think LLMs are bitter-lesson-pilled…”)
Sutton’s Lesson was written in 2019, describing demonstrable dynamics from the history of computing, and he’s certainly largely been proven right. So much so, in fact, that the industry now has “scaling laws” akin to “Moore’s Law,” predicting (incredibly) stable exponential growth in performance indefinitely into the future.
2025, however, has demonstrated that marginal returns to scaling appear to be faltering, and Choi’s talk expanded upon those observations. Scaling, Choi argued, has delivered bigger and better models, but not uniformly smarter ones. This “jagged performance” suggests fundamental limitations in the Sutton-inspired “more is more” approach: simply piling on parameters and data yields diminishing returns in robustness and reliability.
Choi argues (as we have) that such brute-force scaling may not be sustainable and that engineering progress has far outpaced our scientific understanding. The AI community is awash in seemingly contradictory papers, leaving us scratching our heads: are we truly making models reason better, or just test better?
Dr. Choi’s keynote encouraged the AI community to embrace a deeper, more principled pursuit of reasoning. Moving beyond jagged intelligence will entail patching the gaps with both algorithmic ingenuity and analytical rigor.
The exciting takeaway is that we’re beginning to see the path forward (I have previously called it the “Forgotten Path”): with persistent training, smarter RL algorithms, and gradient-guided data, we can elevate smaller models to punch above their weight and push the frontier of reasoning.
Is RL just an echo chamber?
In theory, optimizing LLMs with Reinforcement Learning (RL) – especially Reinforcement Learning with Verifiable Rewards (RLVR) – should produce better reasoning strategies. RL-style optimization played a meaningful role in the DeepSeek moment, but as with many recent developments in this incredibly fast-moving industry, we may have rushed to over-index on early success. In fact, a number of studies and prominent AI personalities (Dwarkesh is bearish on RL, for example) paint a far messier picture of reality.
Several teams found that current RL training often fails to unlock fundamentally new reasoning in models; instead, it tends to amplify the patterns the model already knows. For instance, a Tsinghua University study demonstrated that RL doesn’t yet *actually* induce new reasoning (i.e. better intelligence) beyond what’s already available in the base model. They observed that RL-trained models excel at Pass@1 (getting the answer right in one try) but do no better than the original model when allowed more attempts (Pass@k for large k).
Harvard researchers went further, calling the phenomenon an “echo chamber”: RL fine-tuning tends to narrow a model’s outputs to high-reward patterns it already knows, reducing diversity and exploratory reasoning. As RL training progresses, in-distribution accuracy rises while out-of-distribution performance actually drops, implying the model is overfitting to the reward and losing breadth. The model becomes confident and precise – but only within a smaller slice of its original capabilities.
Then there’s the “spurious rewards” paper from the University of Washington where researchers found that Qwen-2.5 (a Chinese LLM) improved at math even when trained with entirely nonsensical rewards.
The point is, current papers paint a mixed picture of RL for reasoning. Yes, RL and its multiple iterations can refine model outputs and boost single-shot accuracy. But “effortless” RL solutions – quick reward tweaks or naive training runs – often yield hollow results because models become narrowly optimized for the given verifier or reward function, trading breadth for precision. This manifests as high accuracy on the reward’s terms but a failure to generalize or truly deepen the model’s understanding.
It’s a classic incentive perversion (Munger would be proud!): you get what you reward, and if you reward the wrong thing (even inadvertently), you might end up in an echo chamber of well-rewarded mediocrity.

New Strategies to Train for Reasoning
So is all hope lost for RL? Of course not, and Dr. Choi didn’t outright dismiss RL, either. Instead, she called for making RL work harder and smarter to genuinely expand a model’s reasoning. That primarily boils down to different (read: smarter) ways to structure current model improvement mechanisms and flat-out better algorithms across the board.
It almost goes without saying, but at Nazaré we’ve called this “doing more with less,” in order to optimize and improve what already exists. Lest we lose sight of progress in the endless pursuit of “more,” what we’ve built already is incredible and worth appreciating. Optimizing what already exists is a form of respect for what’s been built, as opposed to obsessive, continued brute-force capital expenditure and “fighting the last war”. From an investment perspective, it is also a materially better proposition.
Dr. Choi highlighted a series of innovations that might help to break RL out of its echo chamber. One such approach is Prolonged Reinforcement Learning (ProRL). The idea behind ProRL is simple: don’t quit training too early. Where most RL fine-tuning runs for only a few hundred steps and often on a single domain (e.g., just math), ProRL extends training to thousands of steps across diverse tasks. By giving the model a longer leash and a richer diet of problems (math, coding, logic puzzles, science questions, etc), the model can continue to improve beyond the apparent plateaus that stymied earlier efforts. Using ProRL, a relatively small 1.5B model was trained to become one of the strongest 1.5B-class reasoning models reported to date.
Alternatively, the researchers found that with enough time and varied challenges, the model started developing solution strategies that were absent in the base model. It wasn’t just picking better answers from the same set, it was finally producing new approaches altogether. In short, RL can expand a model’s reasoning boundary, if done thoughtfully.
You may notice that this challenges the earlier pessimism – it suggests that the limitations of RLVR might be methodological, not fundamental. With better practices (like longer, more diverse training), RL can indeed “teach an old model new tricks.”
Dr. Choi also discussed improved RL algorithms to maintain a balance between exploration (trying new ways of reasoning) and exploitation (refining known good strategies). One such method is DAPO: Decoupled Clip and Dynamic Sampling Policy Optimization. Traditional RL uses a technique called clipping to keep the policy updates stable, but it can inadvertently reduce exploration by overly constraining changes. DAPO “decouples” the clipping bounds, allowing the policy to sometimes “clip higher” (read: increase the probability of previously unlikely tokens beyond normal limits). This tweak acts like loosening the reins: it encourages the model to consider more out-of-the-box continuations instead of staying safe. In parallel, dynamic sampling focuses training on the right problems: it filters out data points that are either too easy (model always right) or hopelessly hard (model always wrong). By concentrating on the in-between cases, the training signal remains informative and diverse. Together, these changes fight the dreaded entropy collapse problem – where an RL policy prematurely becomes too confident in a narrow set of answers, losing the entropy (uncertainty) that drives exploration.
These methods show that carefully tuning how the model learns, not just how much it learns, makes a real difference. By keeping the model’s “imagination” alive (high entropy) while still honing in on correct reasoning, they aim to avoid the lure of spurious rewards and mode collapse.
Choi made a joke that RL for reasoning is a bit like raising a child: if you’re too strict or give candy for the wrong behaviors, you end up with a savant who only aces tests without true understanding. (Karpathy also makes reference to learning more like humans & animals, FWIW). The new RL methods instead act like a balanced curriculum and a patient teacher, rewarding improvement while preventing bad habits. In short, if standard RLVR was just making models “better pickers” of existing answers, the new approaches strive to make them “better thinkers” that venture beyond their initial knowledge.
New, Better Tools
Finally, Choi’s keynote turned to a forward-looking question: How do we measure and induce progress in reasoning? If our goal is to push the boundaries of what LLMs can reason about, we need better compasses and maps, not just benchmarks.
Choi advocates for what she calls Gradient-as-Data Perspective. This technique treats gradients and training dynamics as analyzable data rather than focusing solely on model outputs, using tools like “training dynamics atlases” to visualize learning trajectories and identify task interference patterns or shared reasoning strategies. This gradient-based analysis reveals structural insights about model capabilities and enables the design of more effective curricula and multi-task training schedules by understanding which reasoning pathways emerge naturally and which remain underdeveloped.
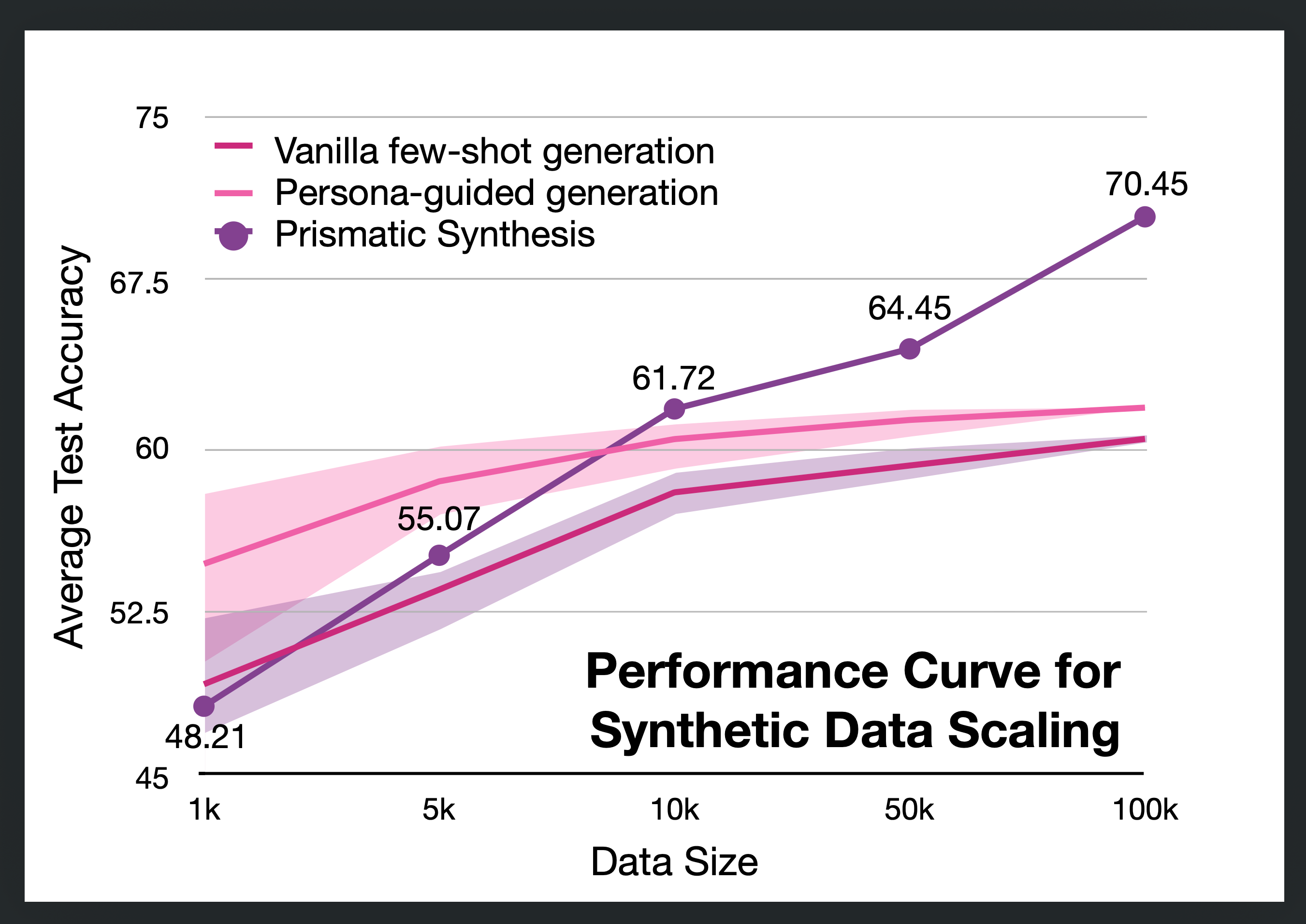
Prismatic Synthesis – Developed by Choi and colleagues at NVIDIA, this is a specific application of this gradient-as-data philosophy, where the team uses gradient diversity (measured by G-Vendi) to guide synthetic data generation. It introduces G-Vendi (Gradient-based Diversity Index) to measure training data diversity based on the entropy of loss gradients rather than surface-level proxies, then uses this metric to systematically generate synthetic data targeting underrepresented reasoning patterns. Strategic data diversification can achieve superior results compared to models trained with massive scale alone.
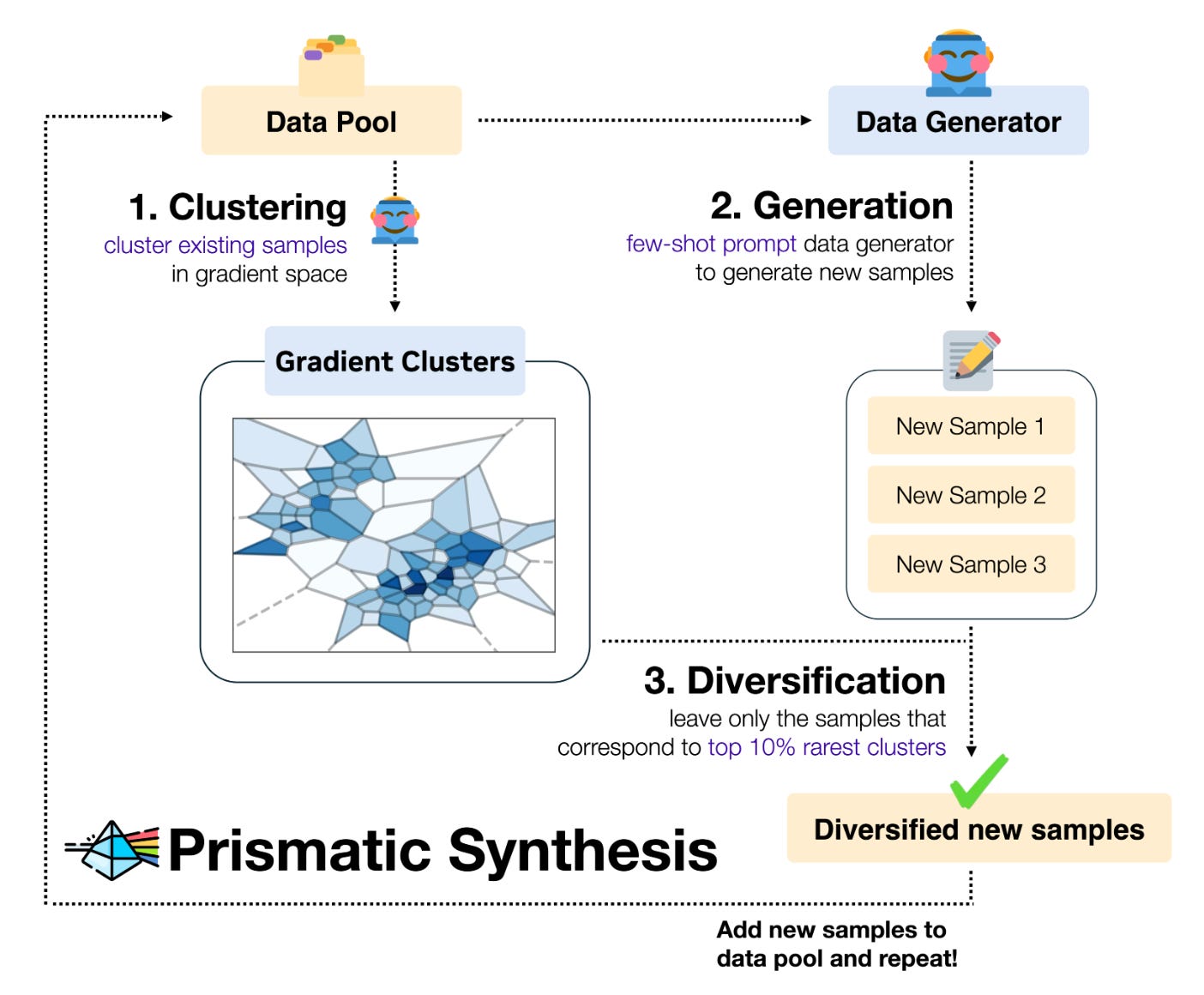
G-Vendi Score for OOD Prediction – As noted, G-Vendi gives a quantitative handle on generalization potential. Choi suggests that we might use metrics like this to evaluate models more rigorously before deploying them. Instead of blindly trusting a high test accuracy (which might be inflated by overfitting or biased data), one could check if the model’s training gradients were sufficiently diverse. A low G-Vendi on the training set would raise a red flag that the model might fail on edge cases or novel problems. This is akin to stress-testing a model’s mind: did it learn only a narrow trick, or a broad skill? As the community grapples with making AI more reliable, such diagnostic scores could be invaluable.
Conclusion
Ultimately, bigger models can still have jagged blind spots, and quick-fix RL can inflate scores without real understanding. The art of artificial reasoning, as Dr. Choi frames it, lies in the care and insight we put into optimization and evaluation:
From brute-force to nuance: Instead of only asking “How can we make the model larger or train it longer?”, we ask “What specific capability is it lacking, and how can we target that?” The answer might be a crafted training scheme (ProRL) or curated synthetic data (Prismatic) rather than just more data. It’s a shift from viewing the model as an opaque giant to treating it like an evolving learner with strengths and weaknesses.
Diagnostics > benchmarks: The talk encouraged a scientific approach to match the engineering prowess. If two methods both get 80% on a test, but one did so by narrowing its solution set and the other by expanding it, we need tools to tell the difference. Pass@k metrics, empirical support charts, and gradient entropy measures all improve our ability to evaluate progress. We’re moving toward a world where we grade the model’s answers AND inspect how it got there.
“Effortful” optimization: Optimizing reasoning in AI will require an iterative, mindful process, blending theory-driven ideas (like GRPO vs PPO, or KL-regularization to prevent reward hacking) with empirical tuning.
I’d like to thank Dr. Choi for her outstanding talk.