

Artificial Good Enough Intelligence
Open weights and what the AI boom will ultimately have left behind

Apr 27, 2026
Most of the attention paid to artificial intelligence concerns the “frontier.” The industry and the media are obsessed with the latest model, its capabilities, and which lab released it, feeding the hyperbolic headlines that present AI as creating infinite abundance or apocalyptic doom.
An outrageous chart like the one below, for example, was published unironically by the Dallas Fed last year and covered in all major news outlets.
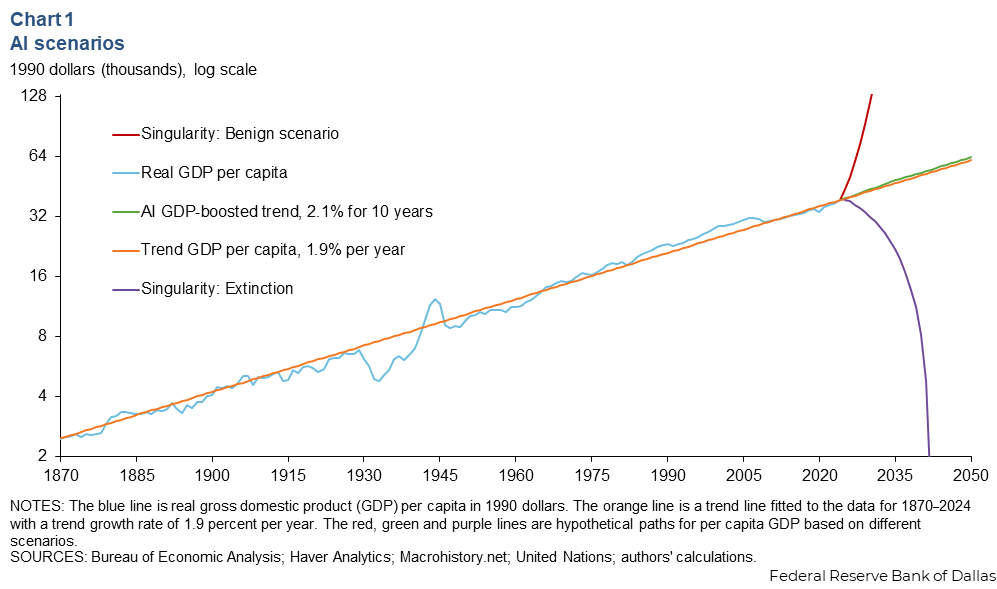
Now, the frontier is extremely important: AI is advancing so fast that it’s hard to keep up, and legitimate improvements in model quality, capability, and products seem to get released almost weekly.
But the frontier may not be publicly available much longer.
Mythos: The Beginning of the End of the Frontier
Earlier in April Anthropic announced it wouldn’t release its latest model “Mythos” to the public. The model was too good at exploiting vulnerabilities in production-grade code critical to the internet and society, and thus too dangerous to release publicly. As usual, Anthropic dominated the headlines.
The withholding is consistent with Anthropic’s long-standing position as the safety-conscious frontier lab: they’ve argued that AI poses existential risk to society despite continuing to push the frontier and building ever more powerful, and thus dangerous, models.
It’s worth noting that with an IPO widely expected before the end of the year, the decision to restrict Mythos reinforces a narrative that also happens to be good for their reputation, fundraising efforts, and eventually, their share price.
None of that, however, means the safety concerns should be discounted or taken lightly, and Anthropic ultimately decided to do two things:
Share Mythos with a limited consortium of companies and stakeholders to fix the vulnerabilities
Release a separate, more cautious public model, Opus 4.7, that omits the cybersecurity capabilities that made Mythos too dangerous to ship
Anthropic hasn’t described Opus 4.7 in those terms, but the timing and the public framing make the inference straightforward: the model the public gets is the model the public is allowed to have.
Mythos won’t be the last time a frontier model is withheld from the public; it’s but the beginning of a trend we should expect to continue. Going forward, the best models will increasingly remain closed, restricted, or selectively exposed.
But if the AI boom doesn’t actually leave the public with access to the best frontier models, what remains in the wake of this extraordinary technological revolution?
Three Layers & A Public Good
I foresee three tiers of intelligence developing over time.

At the top sits the frontier, no longer publicly accessible. The labs will retain these models for themselves and use them to solve the hardest problems that require the most compute. These include (but aren’t limited to) pushing the boundaries of science, math, medicine, robotics, and more. It follows that governments will demand access, primarily for military and national security reasons, which they’ll eventually be granted whether the labs do so willingly or not. (OpenAI and xAI have already willingly given access to the US government. Anthropic can fight the Pentagon for now, but this won’t last long.)
In the middle are the publicly-released commercial models. These are like Opus 4.7: productized versions specifically designed for public consumption, with capabilities trimmed where the labs deem necessary. They’ll be increasingly capable, they’ll feature guardrails and “safety stacks” designed to prevent misuse, but they’ll exist primarily to continue generating revenue for the labs that release them.
The final tier is made up of “open weights” models like DeepSeek, Qwen, GLM, Kimi, and what’s left of Llama. Open-weight models are defined by the public release of their final, fully-trained parameters, known as “weights.” Once published, anyone can download the model for free from HuggingFace, run it, fine-tune it, distill it, and build a product on top of it.
With the exception of Llama, all of these models are Chinese, which is largely a consequence of the choices US labs and policymakers have made. Meta is a great example of the closed frontier, for example. It has pivoted from producing open weight models like Llama to in-house, unreleased proprietary models they use for themselves. The US frontier labs (OpenAI, Anthropic, Google) never released open weights at frontier scale to begin with, and have grown more closed over time. The Chinese labs, partly for strategic reasons and partly for ideological ones, have leaned in the opposite direction.
Open weights models are available to the public no matter what the frontier labs choose to do. They are, in the strict economic sense, a “commons” rather than a public good: non-rival, in that anyone copying them costs no one else, but rivalrous in compute, since running them still requires hardware.
But that subtle distinction doesn’t matter all that much. I believe the open weights ecosystem is the only actual enduring artifact that could outlast the competitive dynamics of any individual lab, a financial meltdown (inevitable, in my opinion), or whatever else the industry may be confronted with.
What Booms Leave Behind
If you ask an LLM what the current AI infrastructure buildout resembles, it’ll tell you about the railroads of the 1860s, the electricity rollout of the 1880s, or the telecom boom of the late 1990s.
It’s describing various technological revolutions and their recurring features: enormous capital requirements, financial speculation that becomes a bubble and eventually busts, extravagant fortunes made by the winners, and equally-large fortunes destroyed by everyone else.
These revolutions also often leave some form of infrastructure behind in the wake of the capital cycle that becomes part of the fabric of the economy known as “public goods.”
One might think the physical infrastructure associated with AI (data centers, GPUs, transformers and more) could itself eventually become a public good, but it’s controlled by the frontier labs at the moment, and “public goods” of this kind typically emerge only after the speculative financial cycle powering its buildout had collapsed.
That being said, the almost inconceivable scale of the AI buildout has produced extraordinary models that are incredibly useful, and although that utility is largely owned by the frontier labs, open-weight models are being produced, released, and improved while the capital cycle is in full swing.
Artificial Good Enough Intelligence
The frontier obviously still wins on the hardest (and perhaps most valuable) tasks. As I mentioned, the most capable versions of AI will be kept in-house and used to solve existential-scale problems that require enormous resources.
But focusing too much on the frontier misses the point: most workloads don’t need the frontier in the first place.
Open models aren’t the “best,” but in many cases they don’t have to be. They only need to be good enough to create real value for real people. A 2016 article on Demis Hassabis in the Guardian (thanks to Sebastian Mallaby for including this citation in “Infinity Machine”, his brilliant new biography of Hassabis), describes artificial general intelligence (AGI) as follows:
This is artificial general intelligence (AGI), with the emphasis on “general”. In [Hassabis’] vision of the future, super-smart machines will work in tandem with human experts to potentially solve anything. “Cancer, climate change, energy, genomics, macroeconomics, financial systems, physics: many of the systems we would like to master are getting so complex,” [Hassabis] argues. “There’s such an information overload that it’s becoming difficult for even the smartest humans to master it in their lifetimes. How do we sift through this deluge of data to find the right insights? One way of thinking of AGI is as a process that will automatically convert unstructured information into actionable knowledge. What we’re working on is potentially a meta-solution to any problem.”
That last line is critical, because Hassabis is describing the frontier: “what we’re working on is potentially a meta-solution to any problem.” In pursuit of Artificial General Intelligence (AGI) writ large, the frontier and its increasingly capable models are absolutely critical, because the problems they’re solving for are extremely difficult and complex.
But as it relates to the public, they actually only need models capable enough to provide efficient “meta solutions” for their own problems, not the broader world’s problems.
In short, they need Artificial Good Enough Intelligence (AGEI), and open models may already be most of the way there.
AI in this sense mirrors what Wired called the “good enough revolution” in 2009, watching MP3s beat CDs and Flip cameras beat camcorders despite losing every benchmark that mattered to incumbents. Christensen had described the same dynamic decades earlier as low-end disruption. AGEI is what happens when that pattern arrives at general-purpose intelligence.
The Implications of AGEI
Over-indexing on the frontier and what makes headlines ignores the fact that general-purpose AI may optimize for something other than capability.
Artificial Good Enough Intelligence has four axes: capability, affordability, availability, and sovereignty.
Put simply, most users (including companies that use AI in their products) need models that are capable, affordable, available, and under their own control. Optimizing for those criteria shifts attention from raw benchmark supremacy (although benchmarks are increasingly unreliable anyway) toward cost, accessibility, and ownership.
Open weights win three of the four axes outright. On capability, they are good enough for most workloads. On affordability, they are dramatically cheaper. On sovereignty, they are by definition fully owned: a model you can version-pin, run offline, and cannot have rate-limited or deprecated out from under you. Only on availability, in the narrow sense of “no infrastructure required to run them,” do hosted closed models retain an edge, and even that is shrinking quickly as serverless inference and consumer hardware close the gap.
That’s why Martin Casado of a16z was quoted as saying: “I’d say 80% chance [AI entrepreneurs we talk to are] using a Chinese open-source model.” Casado later clarified on X that 20-30% of the startups he sees use open source at all, which puts Chinese models in roughly 16-24% of the total. Even after the correction, a meaningful share of the next generation of US AI startups is still being built on infrastructure produced by labs the US government is openly accusing of industrial-scale IP theft.
Case-in-point, Cursor launched a new model called Composer 2 in March promoting it as “frontier-level coding intelligence” without disclosing that it started from Kimi K2.5, the open-weight model from Moonshot AI. Cursor’s defense, once a developer surfaced the model ID in API traffic, was that only roughly a quarter of the final compute came from the Kimi base. The remaining three quarters were Cursor’s own training. Fair enough. The point isn’t that Cursor copied Kimi; the point is that the company building one of the fastest-scaling B2B products in software history chose a Chinese open-weight model as its starting line, and then preferred not to mention it.
The Kimi episode is one symptom of a deeper economic problem. Evan Armstrong, in his write-up of SpaceX’s recent $60 billion call option on Cursor, captured the math: Cursor’s top-line numbers are spectacular. They hit $2 billion ARR, 14x year-over-year, fastest B2B SaaS to $1B ARR ever, beating Slack by two years. The unit economics underneath are spectacularly awful. In January 2026, gross margin was negative 23%. Every $1 of revenue cost $1.23 in API spend to Anthropic and OpenAI. At $2B ARR, that’s $2.46B annualized flowing directly to the companies building competing products. This is like paying to send the guy planning to kill you to stabbing school. Cursor was funding its killers.
Despite their capabilities, sometimes using the frontier models just isn’t optimal, and open-weight models aren’t only necessary, but better-suited for a given use-case.
There’s also sufficient infrastructure in place to ensure that open models continue to improve with or without the frontier labs. DeepSeek V3, released in late 2024, was trained on export-compliant H800s for ~$5.5 million in final training run cost, roughly 5-6% of what comparable Western frontier models reportedly cost. V4, released last week, was trained entirely on domestic Chinese hardware: Huawei Ascend 950 chips and Cambricon accelerators, with barely (if any) Nvidia silicon involved at all.
That means the export restrictions on H100s didn’t exactly stop Chinese frontier development, instead pushing it onto a separate (domestic) hardware stack that they control.
In fact, the open ecosystem may already have reached something like escape velocity, simply because the recursive improvement tools now available (Distillation, Reinforcement Learning (RL), and cheap hardware) may be sufficient to continuously improve open models whether or not the frontier labs keep releasing their best work.
What’s more, once models are trained, users will be able to run them on consumer hardware with enough RAM. Quantization, the technique of compressing model weights to lower precision, makes this dramatically easier, at the cost of some model quality. The trade is improving fast: a 4-bit quantized 70-billion parameter model in 2026 is meaningfully closer to its full-precision parent than the same compression would have produced two years ago, and the curve is still bending. In short order, the open ecosystem will lower costs, reduce dependence on frontier API providers, and make intelligence far more durable for end users.
The China Concession
One genuine risk to this thesis is geopolitical: the open-weight ecosystem is now largely a Chinese ecosystem, and Chinese policy on AI release is not guaranteed to remain as permissive as it has been. A future in which Beijing decides open weights are a strategic asset to be controlled is plausible.
Even in that future, however, the weights already in circulation do not disappear. The DeepSeek R1 you downloaded in 2025 still runs in 2030. That is what it means for something to be a public good (or in this case a “commons”).
What We Inherit
The frontier may eventually deliver on its promise of meta-solutions to civilization-scale problems. It may not. Either way, that bet is being made by twelve people in San Francisco and a similar number in Beijing, and the public has no seat at the table.
What the public does have, increasingly, is a parallel inheritance: weights they can download, run on their own hardware, fine-tune for their own problems, and keep forever. Not the best intelligence ever built, but intelligence good enough to materially change what an individual or a small company can do, owned outright, with no vendor that can take it away.
If the frontier solves cancer, we all benefit. If it doesn’t, at least the rest of us got AGEI out of the deal. That is what the AI boom will leave behind, and unlike most of what has been promised in this cycle, it is already here.