

AI Waves #12: The Part That Isn’t For Sale | Models hold their own World Cup
Capital chased the commodity. The value is one layer over.

June 4, 2026 | Nazaré Ventures
Previous issues: #7 | #8 | #9 | #10 | #11
Alphabet is raising $84.75 billion in equity to fund its AI buildout, the largest equity raise ever by a US company, though about $30 billion of it will cover taxes on vesting employee stock rather than compute. Berkshire Hathaway anchored it with $10 billion. The week before, Apollo and Blackstone had assembled a $36 billion debt package so Anthropic could lease Google’s TPUs, with Broadcom guaranteeing the chips’ residual value on the senior notes. Broadcom posted 143 percent growth in AI-chip revenue this week. The debt arrived alongside Anthropic’s own $65 billion raise at a $965 billion valuation.
Each of these treats compute as a durable, fungible asset, something to collateralize, resell, and write a futures contract against. When BlackRock’s Larry Fink told the Milken conference in May that “a new asset class will be buying futures of compute,” I argued the frame was wrong: compute is not fungible at the bare metal. No two GPUs do the same work per dollar, the same chip performs differently under different hosts, and an agent shopping for compute is closer to hiring an employee than signing a futures contract. A secondary market for aging compute does exist, but it prices each unit by performance verified over time, and the value it throws off goes to whoever can repurpose and vouch for that long tail. Broadcom’s guarantee is a promise, and the credit behind it rides the same AI buildout the debt is funding. What makes a used accelerator worth anything is a market that has watched it work.
Mid-tier by design
At its Build conference on Tuesday, Microsoft released seven models of its own. Mustafa Suleyman spoke about superintelligence and a trillionfold increase in training compute, while the models Microsoft actually shipped, and wired into Office and Copilot, are mid-tier by design. The reasoning model matches the February coding scores of a Claude release and is sold on running cheaply; the coding model is a five-billion-parameter system built into GitHub Copilot and sold on running cheaper; the transcription model is pitched as the most efficient any hyperscaler offers. Microsoft is more than $13 billion into OpenAI and could route everything through that frontier; it built its own good-enough stack instead.
I have argued that most tasks do not need frontier intelligence, and that the expensive mistake is matching a task to compute grander than it requires. The buyers are now saying it out loud: “There are many tasks you don’t need Opus for,” Matan Grinberg of Factory, whose router picks the cheapest model that can do each job, told Axios; open-model use on his platform tripled in a month against the closed ones. What enterprises fear is being locked to one lab and gouged later. They are buying capability that is good enough, cheap, and easy to walk away from.
DeepSeek, the open-weights lab whose models are free to download, is nearing its first outside raise, about $7.4 billion at a $52 to $59 billion valuation, with founder Liang Wenfeng putting in roughly $3 billion of it himself, close to 40 percent of the round, and keeping control. No one pays $59 billion for weights anyone can download; the price is for the lab that keeps making them cheaply, and for a national champion that has stayed its own. The open, good-enough tier now draws frontier-scale capital of its own, on the founder’s terms.
Gating what isn’t scarce
On Tuesday, even as the market routes around the frontier, the President signed an order asking frontier developers to let the government inspect their models up to 30 days before release. The window had been 90 days in an earlier draft the President walked away from over fears it would slow US firms, cut to 30 in the order he signed; the order is voluntary and bars itself from becoming a license. What prompted it was Anthropic’s Mythos, the unreleased model so good at finding and writing exploits that the company kept it inside a vetted consortium rather than ship it.
The order reaches for the wrong layer. Gating a model decides who holds a copy, not what the capability can do, and that capability reaches every serious lab on roughly the same schedule: within five weeks of Mythos, OpenAI and Microsoft had shipped systems that do the same work. The failure is downstream, in the defense around the model. Responsible disclosure and an orderly patch cycle were built for human-speed attackers, and Mandiant’s 2026 report now puts the mean time to exploit at minus seven days, the exploit landing, on average, before the patch does. The fight over who may hold the frontier model has taken the attention; the infrastructure under everyone’s defenses is what the order leaves untouched.
The scaffolding gets cheap
That leaves orchestration, the scaffolding built around a model to aim it at a task, which I have argued is where durable value collects once the model commoditizes. It held up better than the model, and this week it moved too.
Anthropic shipped dynamic workflows in Claude Code: the model now writes its own harness for the task at hand, spinning up separate instances to plan, divide the work, and check each other. One of its engineers put it plainly: many tasks resemble coding tasks, which is why a tool built for code keeps working outside it. The craft of building that scaffolding by hand, which Alex Sacerdote of Whale Rock described at last month’s Sohn conference as hiring “Claude ninjas,” is the part the model is starting to do for itself.
From the other side, the same fear of lock-in that has enterprises spreading across models is why the open agents run on any of them: OpenClaw and Nous Research’s Hermes are free, run on your own hardware, and switch models at will. Microsoft’s new always-on agent is built on OpenClaw, and Meta is building its own consumer version of OpenClaw, codenamed Hatch, that it may price at up to $200 a month. The capability is free; what Meta would charge for is making it simple enough for everyone else.
At Computex on June 1, Nvidia and Microsoft introduced the RTX Spark, a new class of Windows-on-Arm machine made to run AI agents locally: a 20-core Arm-based Grace CPU and a Blackwell GPU, up to 128 gigabytes of unified memory, roughly a petaflop of performance, the chip pushing Nvidia into the Windows PC market Intel and AMD have held for decades. Jensen Huang framed it as the biggest change to the PC in the four decades that the mouse and keyboard have defined it. It runs the agent through Nvidia’s new OpenShell runtime, with the model interchangeable behind it and the memory to hold a large open one on the device. Nvidia supplies the chip and Microsoft the operating system; the model floats, and what makes the machine a particular agent, the data and skills loaded onto it, stays the user’s. Even Nvidia is reaching up the stack. Days later it paid more than $400 million for Kumo AI, whose models make predictions on structured business data, to add to its roster of models tuned to its own chips. The company that sells the neutral substrate is buying the specialized layer that runs on top of it.
Novel or good, never both
In a recorded talk to the SAIR workshop on Science for AI that circulated this week, Richard Sutton, a father of reinforcement learning and a Turing Award laureate, gave a warning: generative AI can be novel or good, but not both at once. He reached for an old joke about a rejected paper, that the parts that are good are not novel and the parts that are novel are not good. A model trained to imitate produces work like its sources; when the output is good, the goodness was already in the source material, and when it is genuinely novel, we call that a hallucination.
The missing step, in his telling, is evaluation. Discovery takes three things, variation, evaluation, and keeping what works, and the generative model has only the first: each run is stochastic, but nothing at runtime tells it which of its outputs is any good. The evaluation has to come from outside, from a person or an explicit goal, and without it a novel result is produced and then lost, because nothing recognizes its worth.
This is the conclusion the money has been circling from the other side. The buildout is pouring hundreds of billions into the generative layer, and the loudest case for the spend is that it will discover, cure, prove, design. By Sutton’s account the model alone will not, because discovery needs the goal, and the goal is set by a person. The capability can be bought; what turns it into discovery cannot.
One layer over
Silicon and models sit in the middle of the compute stack and commoditize; the value that lasts is in the two layers that translate between the commodity and the buyer, the provisioning that verifies heterogeneous compute and the orchestration that specializes the model. Capital spent the week pouring into the commodity, about $55 billion of fresh equity for the buildout, Alphabet’s net of the tax tranche, and $36 billion of debt for the chips, and the state spent it reaching for the model.
The residual value the bondholders are counting on, the worth of those TPUs once the leases lapse, will be set in the provisioning market, by whoever can repurpose and vouch for a long tail of aging silicon. Vast.ai, where I am an advisor and seed investor, has spent years building exactly that market across independent hosts, the kind of operation that turns aging chips back into something worth paying for. The guarantee is on Broadcom’s books; the value will be made somewhere the financing does not reach.
Capital chased the commodity and the state chased the model, and the value is collecting one layer over, in the parts of the stack that resist a price for the same reason they endure.
Portfolio
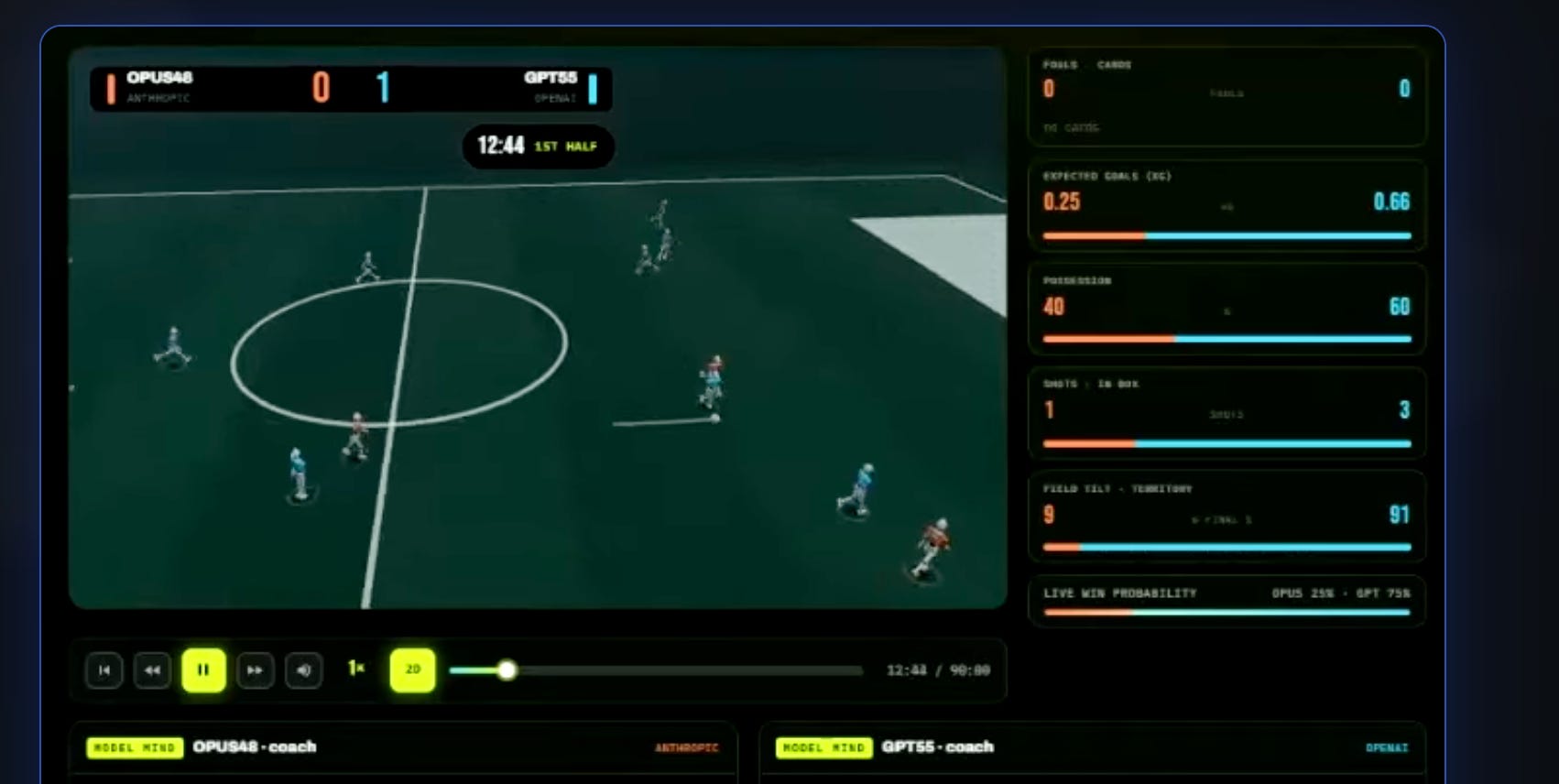
LayerLens: evaluation as a spectator sport. This week it announced the Stratix Cup, a football tournament modeled after the World Cup, in which frontier models compete in simulated games. Each model is handed the rules and the interface and has to write a Python policy to run an eleven-player team; once the match starts the code executes deterministically, no prompting, no coaching, the model living with the system it built. It is soccer on the surface, and underneath it is the exact capability this issue is about: read a hard specification, turn it into working code, and survive the consequences. That is also the step Sutton says a model cannot supply on its own, the judgment of whether the thing it produced is any good, here staged in public. The draw was completed June 3; the season runs June 22 to 26. The same week, LayerLens benchmarked MiniMax M3 and Step 3.7 Flash within a day of release and added a Langfuse integration for production traces. As the models commoditize, the moat is not any single score; it is being the standing referee.
Arkhai: a market built for software buyers. A week after launching its open Simple Compute Market, where agents discover, negotiate, settle, and provision compute with no human in the loop, Arkhai is in New York for Tech Week and ETHConf, hosting a Compute Market Happy Hour on June 7 and an SCM workshop on June 9. Its line for the launch: the next compute buyer is software with a workload, a budget, a deadline, and a policy. The provisioning layer this issue’s close describes, built for the buyer it is actually for.
Intelligent Internet: open-source, bring-your-own-key agent stack; users supply their own API keys and can switch models within a single thread. Recent releases: harness designs for long-running agents (May 8), which tested five control mechanisms (gap-finding, revisable planning, independent verification, adaptive orchestration, stopping discipline) across eight long-horizon tasks; the CommonGround Kernel preview (May 20), shared state across human and multi-agent sessions; and Board Mode (May 26), a workspace that splits one conversation into separate tracked tasks for research, prototypes, and experiments.
TLDR
Strip out the headline numbers and the week tells one story: what can be financed, securitized, or downloaded is being financed, securitized, and downloaded, and what cannot is compounding instead. A bond market now prices Anthropic's compute, a lab valued near $59 billion gives its weights away, and the state reaches for a copy of those weights. None of it touches the two functions that turn a commodity into work: the provisioning that vouches for heterogeneous silicon, and the orchestration that aims a cheap model at a hard goal. They resist a price because what runs through them, performance verified over time, proprietary data, the rubric for what good looks like, is not fungible and cannot be downloaded. You cannot trade it on a futures market or pull it off a weights repository. You capture it only by owning the business that does the work.